[應用] 雲運算之語音辨識 (Speech To Text)
語音辨識架構
隨著雲端運算的技術越來越成熟,各家平台提供語音方面的服務,應用開發者只要連上雲端並將語音上傳,便能取得想要的服務。為了研究如何連上各家平台的服務,筆者設計一個 Proxy 服務,如圖一所示。目前,我們實際使用過的平台有:阿里雲、百度、科大訊飛、雲知聲,每個雲端平台提供服務的連線驗證方式都不一樣,而且雲運算的語音辨識參數也不盡相同,所以設計一個 Proxy Service 將連線驗證與各項參數做成一個統一開放的介面。Proxy 服務讓其他程式、工具、或人機介面透過網路方式連到這個服務上,並上傳語音,之後返回辨識結果。過程中,各平台的驗證以及 SDK 的整合均由這個 proxy 處理掉了。
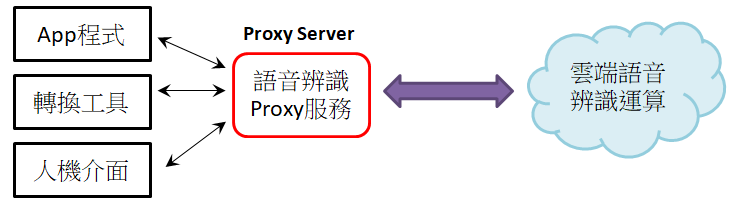
|
|
圖一:語音辨識的 Proxy 服務 |
設計流程
圖二是Proxy Service 內部架構的方塊圖。服務裡有一個 TCP listening 一直等待著其他程式連線,一旦有 TCP 連線,便創建一個新 thread,專門處理這一路連線的通道。由此可知,Proxy 服務可以同時處理多個語音通道,互相獨立運算。另外,圖下方所示,這個服務的底層就是整合多家平台的 SDK,調用他們的 SDK 連上雲端獲得服務。這些 SDK 函數主要功能是封裝 WebSocket 通訊協定,方便開發者調用。當然,我們也可以根據平台的技術文件自行設計一套 WebSocket app 連線雲端,參考 [1][2] ,既然平台有提供 SDK,最好是使用 SDK 來開發,這可避免不相容的問題。
Proxy 服務的核心是提供一個統一開放介面 SRChannel,並可以設定相關參數,如:VAD、silence偵測、silence 長度...等。設計一個存放語音的 queue,並穩定地上傳到雲端。從雲端返回的事件或結果,再傳給對應的程式。

|
|
圖二:Proxy 服務的內部方塊圖 |
實現展示
這裡,我們設計一個音檔轉換工具,透過 Proxy 服務將語音轉成文字。底下影片,採用雲端的語音辨識運算,將wav音檔內的語音轉換成文字的程式。影片右邊是音檔轉換工具程式,影片的左邊是播放音檔的聲音,我們可以左右比對音檔內容與語音辨識後的文字。這個轉換工具將目錄裡面的所有音檔依序轉換成文字,並顯示在底下的表格內。





留言