[工具] 中文自然語言處理 NLP 的開發套件
自然語言處理 (NLP - Nature Language Processing) 主要能讓機器分析對話文字,進而理解對話的意思,這項技術其實已經發展很多很多年了,但在近年來,拜高速網路、海量數據、智能發展之賜,有機會廣泛地應用到實際生活之中,比如聊天機器人、文件資料搜索、演講內容分析...等。開發 NLP 技術的含量很高,需要建立模型、收集大量語料、訓練與運算,一般的開發人員其實很難短時間就能將 NLP 的語意功能實現出來。目前幾個雲端平台的大廠(微軟、谷歌、阿里、百度)有提供 NLP 相關的服務,但所幸在中文自然語言處理領域中有幾個學術單位開發出不錯的模型,並且提供 SDK 工具包給工程人員進行二次開發,常見的中文 NLP 模型有:哈爾濱工業大學的 LTP、中科院的 NLPIR、清華大學的 THULAC...等等,其中以哈工大和中科院的 NLP 模型效果比較佳 (根據網路使用者的比較後,這兩家的 CP 值較高),中科院的 SDK 提供 C# / C++ / Java 這些程式語言的介面,對我們開發者更為便利。本文將介紹中科院的 NLPIR SDK 開發和操作的結果。
首先,我們到 github 網站下載 NLPIR,https://github.com/NLPIR-team/NLPIR,當中有一個 SDK 目錄,裡面存放了 20 種自然語言處理的組件,各個組件的功能說明,如下圖一所示。雖然這套 SDK 提供便利的介面讓大家進行二次開發,但是它有 license 的限制,對於短期測試的開發人員而言,github 上面會定期提供一個月期限的 license,我們只要下載並更新 license 後就能繼續使用 SDK。如果有商業需求的話,則需要購買商業 license,取得長期使用權。下圖中以藍色標示的組件是我實際測試操作過的部分,當中的 NLPIR-ICTCLAS 組件為系統的核心,可以做到中文分詞,將一段句子或文章經過這組件的分析後,切出一個一個詞並標示出名詞、動詞、形容詞、副詞....等詞性,這一刀切的精不精準就代表這套系統優不優秀了。除了處理中文分詞之外,NLPIR-ICTCLAS 同時也能找出句子的關鍵字或有無發現新詞。
另外其他組件,像 KeyExtract 也是搜尋句子或文章中的關鍵字組,它會列出這些關鍵字的權重。SentimentAnalysis 和 SentimentNew 組件用來分析句子中的情緒情感分數,這套 NLP 已經內建各種情緒字詞(如:快樂、邪惡、悲傷...),並經過模型的訓練後能得到文句中的情感指數,這應用在客服系統的後台處理過程能分析出客戶的情緒指數,進而了解服務的滿意度。接著,Classify 和 DeepClassifier 組件用來分析一段話是屬於哪個類別的話題,比如說我們將話題先分類為交通、教育、體育、政治...等規則,這個分類的規則由我們定義並記錄在 rulelist.xml 裡面,所以稱為專家啟發式。當我們輸入一段文字後,經過 Classify 組件分析後,便會回傳這段文字屬於哪一類的話題。DeepClassifier 組件就不是依靠 rulelist 專家的規則,我們需要提供這個組件大量語料,再讓它進行訓練與分類,經過深度學習後所得到的各項分類。之後,我們輸入一段文字後,DeepClassifier 依據之前深度學習後的規則,回傳分類名。
 |
| 圖一:中科院的 NLPIR SDK 所提供的各類組件 |
底下是我開發的程式所執行的結果,圖二顯示輸入一段有關盜版的文字後,執行 SDK 的分析所得到的結果,這段文字在情感上屬於負向的,同時也找到新詞與關鍵字。圖三則是模擬客服中心的對話系統,利用分類的 SDK 分析對話中的文字,得到對方話語可能的意圖,才能進入下一階段的動作。最終,我們希望藉由 NLP SDK 的開發,改善問答系統的服務品質,提升客服系統的效率。
 |
| 圖二:輸入一大段文句後,執行 SDK 的組件分析 |
 |
| 圖三:模組客服系統的場景 |




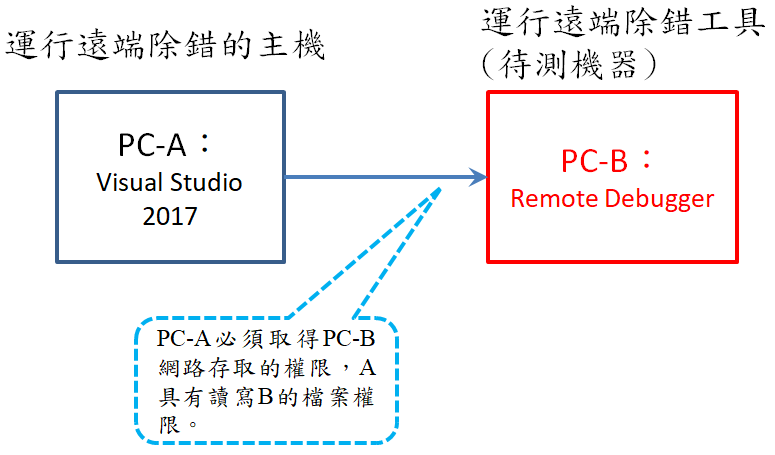

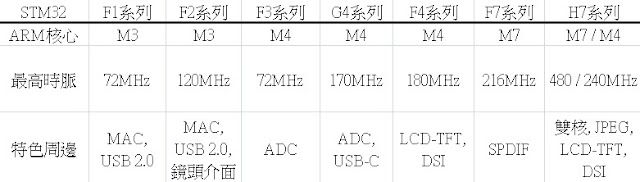
留言